Karpathy知识库「LLM Wiki」火爆了,全网围观讨论
Karpathy知识库「LLM Wiki」火爆了,全网围观讨论Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。
来自主题: AI资讯
8740 点击 2026-04-06 08:51
 搜索
搜索
Karpathy 表示,大多数人使用 LLM 处理文档的方式,基本都类似于 RAG:你上传一组文件,模型在查询时检索相关片段,然后生成答案。这种方式是有效的,但问题在于每一次提问,模型都在从零重新发现知识。没有积累。

官方宣传语:你是否隐隐担忧,自己或身边的人正在:参与一场席卷所有人的技能大退化?遭受 LLM 诱发的?一个名为 Sam Lavigne 的大学教授,最近发布并开源了一款名为「Slow LLM」的 AI 工具。

这两年,扩散语言模型(Diffusion LLM)一直是个很有讨论度的方向。

在此背景下,浙江大学研究团队提出了 EasySteer——一个基于 vLLM 构建的高性能、可扩展 LLM Steering 统一框架。该框架通过与 vLLM 推理引擎的深度集成,相比现有 Steering 框架实现了 10.8-22.3 倍的推理加速,同时提供更细粒度的干预控制,并为八大应用场景提供了预计算 Steering 向量与完整复现示例,方便研究者快速上手和对照复现。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。
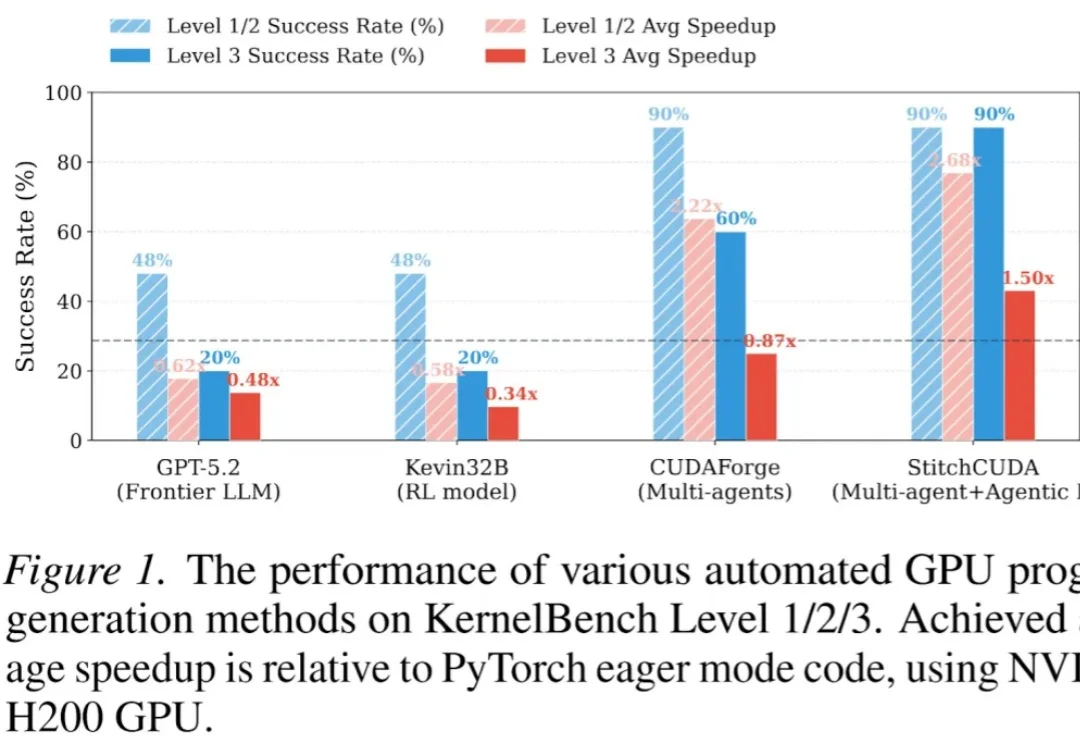
现有的 LLM 自动化 CUDA 方法大多只能优化单个 Kernel,面对完整的端到端 GPU 程序(如整个 VisionTransformer 推理)往往束手无策。

我天!感觉 Seed 1.8 发布还没多久,没想到 Doubao-Seed-2.0 这么快就杀到了…今天发都算是晚讯了。据官方介绍,这次 Seed 2.0 多模态理解能力全面升级,还强化了 LLM 与 Agent 能力,模型在真实长链路任务中可以稳定推进。

近期发表于 TMLR 的论文《Large Language Model Reasoning Failures》对这一问题进行了系统性梳理。该研究并未围绕 “模型是否真正理解” 展开哲学层面的争论,而是采取更加务实的路径 —— 通过整理现有文献中的失败现象,构建统一框架,系统分析大语言模型的推理短板。

近日,微软Bing Ads与DKI团队发表论文《AdNanny: One Reasoning LLM for All Offline Ads Recommendation Tasks》,宣布基于DeepSeek-R1 671B打造了统一的离线推理中枢AdNanny,用单一模型承载所有离线任务。这标志着从维护一系列任务特定模型,转向部署一个统一的、推理中心化的基础模型,从